Kubeflow & Kale simplify building better ML Pipelines with automatic hyperparameter tuning
Running pipelines at scale has never been easier.
- Running pipelines at scale has never been easier
- New Face
- Hyperparameter Tuning
- New features
- Hands-On
- Road Ahead
Running pipelines at scale has never been easier.
TL;DR: Convert Notebook to Kubeflow Pipelines, run them as hyperparameter tuning experiments, track executions and artifacts with MLMD, cache and maintain an immutable history of executions: Kale brings all of this on the table in a unified workflow tool, simple to use.
Running pipelines at scale has never been easier
Kubeflow’s Kale is maturing and fast becoming the superfood that glues together the main Kubeflow components to provide a cohesive and seamless data science experience. With its newest release, Kale provides an end-to-end workflow that encompasses Jupyter Notebooks, Kubeflow Pipelines, hyperparameter tuning with Katib, metadata tracking with ML Metadata (MLMD), and faster pipeline executions with caching.
If you are new to Kale, head over to this short introduction to get started!
In this blog post, you will learn about the features that Kale is bringing to the Machine Learning community with version 0.5, and learn how to get started with a curated example.
New Face
First off, we are excited to reveal the new Kale logo. Kudos to Konstantinos Palaiologos (Arrikto) for designing the brand new, modern Kale leaf. This will be the new face of the project from now on.

Hyperparameter Tuning
The major new addition in v0.5 is the support for running pipelines with Katib. Katib is Kubeflow’s component to run general purpose hyperparameter tuning jobs. Just as you would press a single button to convert a notebook to a pipeline, you can now press a button and let Kale start a hyperparameter Job on that pipeline. All you need to do is tell Kale what the HP tuning job should search for.
Running hyperparameter tuning jobs gives you a dramatic boost in delivering good results for your project. The *manual *tuning process of running your model countless times, using different parameters combinations, aggregating them and comparing them, is error-prone and inefficient. Delegating this work to an automated process allows you to become faster, more efficient and accurate.
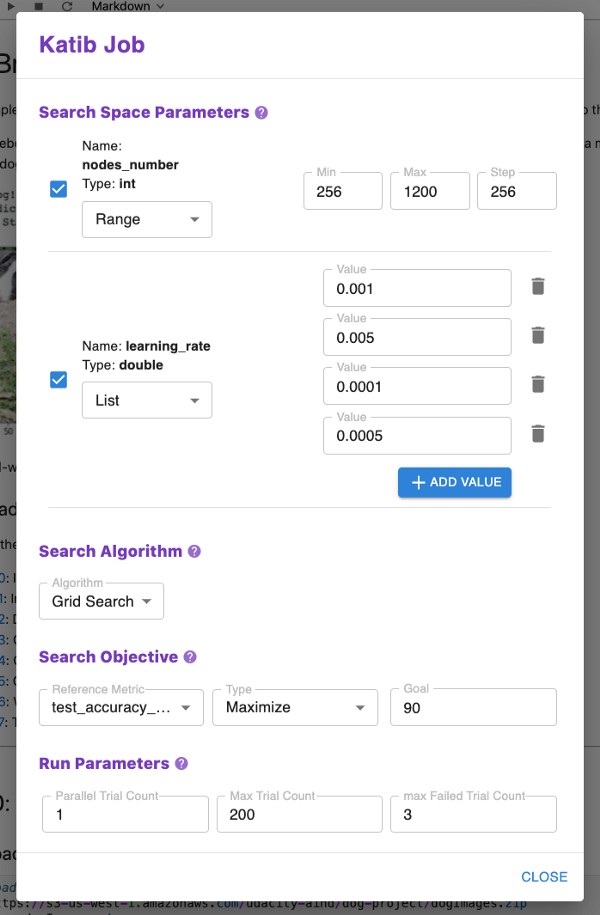
Katib does not know anything about the jobs that it is actually running (called Trials in the Katib jargon). Katib supports running Trials as simple Jobs (that is, Pods), BatchJobs, TFJobs, and PyTorchJobs. Kale 0.5 integrates Katib with Kubeflow Pipelines. This enables Katib trails to run as pipelines in KFP. The metrics from the pipeline runs are provided to help in model performance analysis and debugging. All Kale needs to know from the user is the search space, the optimization algorithm, and the search goal.
Kale will also make sure that all the runs of a Katib experiment, end up unified and grouped, under a single KFP experiment, to make it easy to search and isolate a particular job.
Kale will also show a live view of the running experiments, directly in the notebook, so you will know how many pipelines are still running and, upon completion, which one performed best.
New features
Pipeline parameters and metrics
In order to run pipelines with hyperparameter tuning, the pipeline needs to be able to accept arguments and produce metrics. Enabling the pipeline to do this, is now tremendously easy. Kale provides two new cell tags: pipeline-parameters and pipeline-metrics.
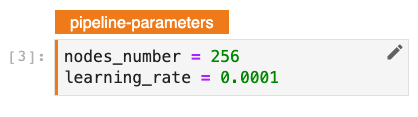
Assigning the pipeline-parameters tag on any cell that contains some variables will instruct Kale to transform them to pipeline parameters. These values will then be passed to the pipeline steps that actually make use of them.
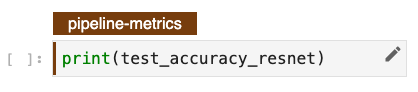
If you want the pipeline to produce some metrics, just print them at the end of the notebook and assign the pipeline-metrics tag to the cell. Kale will take care of understanding which steps produce the metrics and you will see them appear in the KFP dashboard.
Rich notebook outputs
Having your pipelines produce rich outputs (like plots, tables, metrics, …) that can be captured and displayed by the Kubeflow Pipelines dashboard has always been somewhat cumbersome. You would need to write some KFP-specific code to produce json artifacts that would then be interpreted by KFP.
What if you could just write plain Python in your Notebook using your favourite plotting library, and have the plots auto-magically appear as KFP outputs, when the Notebook gets compiled into a pipeline?
Now, when running your notebook code inside a pipeline step, Kale will wrap it and feed it to an ipython kernel, so that all the nice artifacts produced in the notebook, will be produced in the pipeline as well. Kale will capture all these rich outputs automatically and instruct KFP to display them in the dashboard. Effectively, whatever happens in the notebook, now happens in the pipeline as well. The execution context is exactly the same.
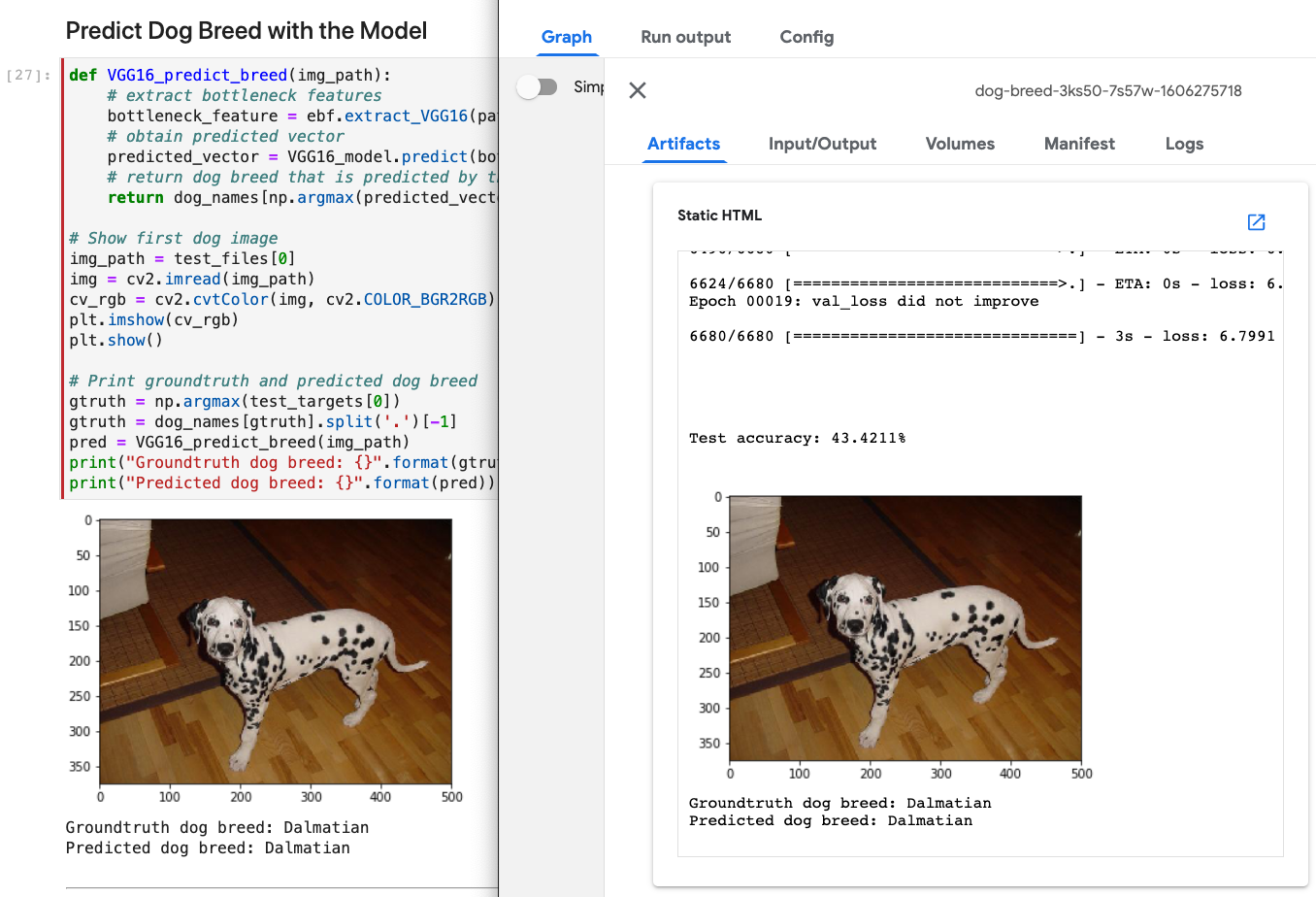 Any rich output that is visible in the notebook gets captured by Kale and exposed in the KFP dashboard.
Any rich output that is visible in the notebook gets captured by Kale and exposed in the KFP dashboard.
MLMD Integration
An important part of running reproducible Machine Learning collaboratively and at scale, is being able to track pipeline executions, their inputs, their outputs and how these are connected together. Kubeflow provides an ML Metadata service which serves this exact purpose. This service also includes a lineage view to enable the user to have a deep insight into the whole history of events.
Kale is now fully integrated with this service, logging each new execution automatically alongside all the artifacts produced by the pipeline.
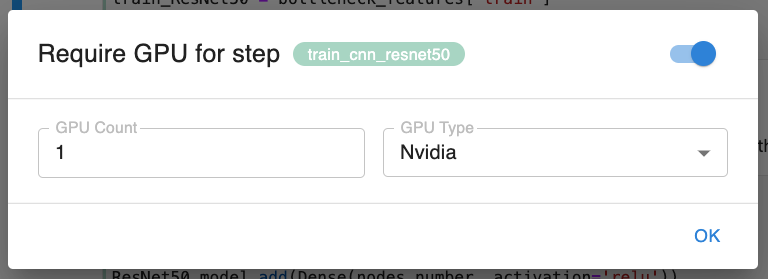
Run on GPU
If you need to run a particular step on a GPU node, Kale has you covered too. You can now annotate steps with a dedicated dialog, directly from the notebook and each step can have its own annotations. This is just the first iteration, Kale will support adding any kind of K8s limits or annotations to pipeline steps in the near future.
Overall UI and performance improvements
The new version of Kale’s JupyterLab brings tons of performance improvements and UI enhancements. Updating the notebook cells’ annotations will now be easier and faster. We covered many corner cases and solved tons of bugs. The UI of the cell’s annotation editor is more consistent with the overall Jupyter style and much more intuitive and easy to use. A big shoutout to Tasos Alexiou (Arrikto) for having spent countless hours in understanding the Jupyter internals and improving our application lifecycle.
Hands-On
To start playing-around with Kale v0.5, head over to the GitHub repository and follow the installation instructions. If you are already running Kubeflow (either in your own cluster or on MiniKF), spin up a new Notebook Server using the image gcr.io/arrikto/jupyter-kale:v0.5.0.
Note: Kale v0.5 needs to run on Kubeflow ≥ 1.0. Also, make sure that the following Kubeflow components are updated as follows:
-
Katib controller: gcr.io/arrikto/katib-controller:40b5b51a
-
Katib Chocolate service: gcr.io/arrikto/suggestion-chocolate:40b5b51a
We will release a new version of MiniKF very soon, containing a lot of improvements that will make the Kale experience even better. You will also be able to go through a new Codelab to try out the Kale-Katib integration yourself. Stay tuned for updates on the Arrikto channels.
Road Ahead
We are always looking to improve Kale and help data scientists have a seamless ML workflow from writing code to training, optimizing, and serving their models.
We are excited to have the ML community try out this new version of Kale and the coming MiniKF update.
A special mention must go to the various members of the Arrikto team (Ilias Katsakioris, Chris Pavlou, Kostis Lolos, Tasos Alexiou) who contributed to delivering all these new features.